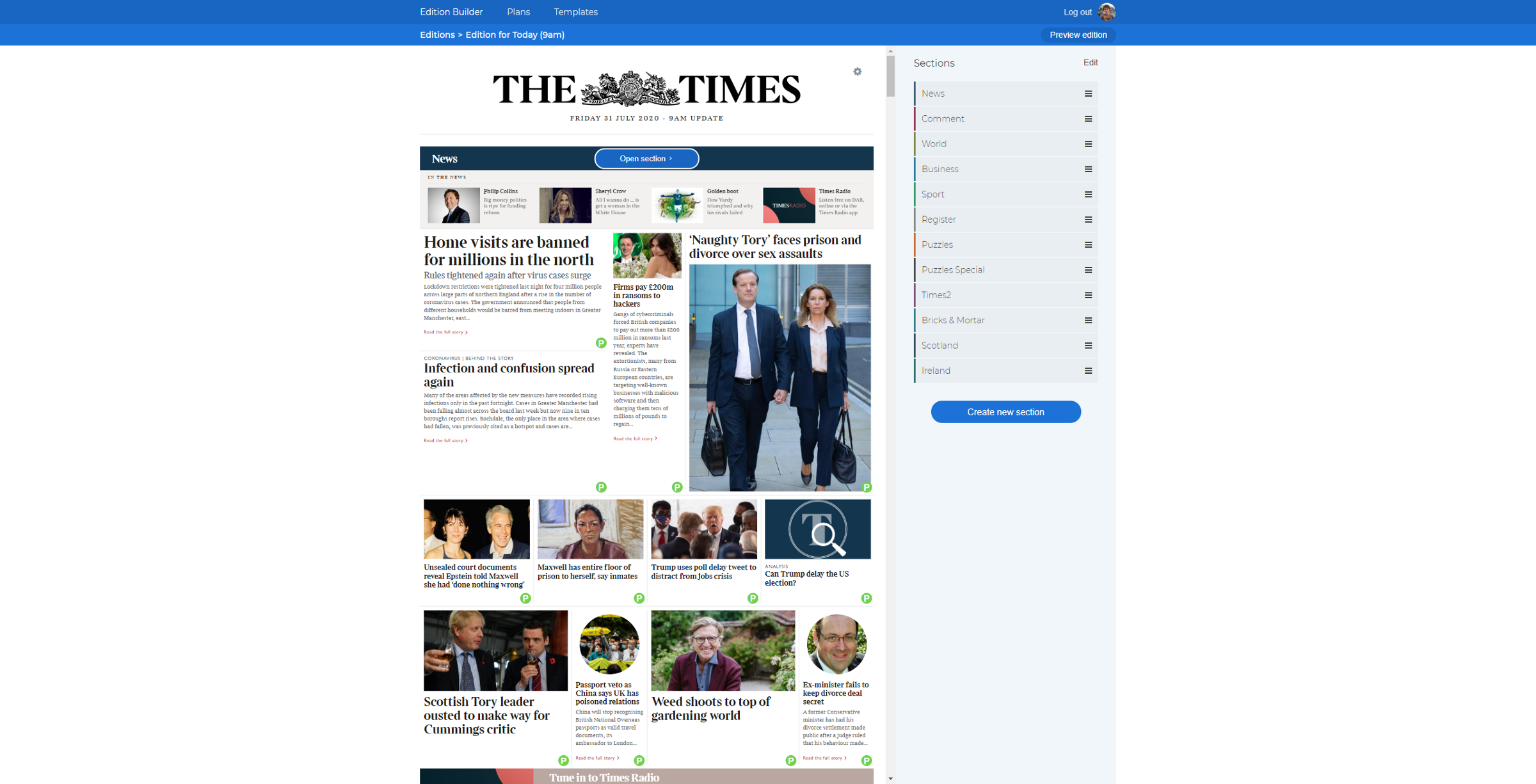
What we learned from rebuilding the editions CMS for The Times
3 August 2020
In the last post I took you through a short summary of what it took to get Edition Builder live at The Times and Sunday Times. If you haven’t read it, you should, it’s pretty good background.
(In the last post I also mentioned I’d be writing this in a few weeks. That was pre-coronavirus, so these posts have taken a seat at the very back of a very long series of seats. Apologies for that!)
As one of the larger engineering projects we have undertaken, Edition Builder broke new ground in a bunch of areas. We tried things that we hadn’t attempted before, and pushed systems to their limits (and well past them in one incident).
There were a lot of challenges we encountered as a team that we had to work out how to navigate. Though its not likely that you’ll learn a lot about the specific issues we encountered, I hope there are patterns you can recognise that are best avoided, and things you can think about should you work on anything similar.
Searching for articles
Search in Edition Builder was, for most of its life, unworkable. I don’t know why I persisted so long convincing myself that it would work, but it was only ever going to get worse from the moment we realised this problem. Not raising this earlier in the lifecycle of the project was a big mistake from me, I think because I thought it was unsolvable, but as with most things online, someone else has usually solved the problem you are facing, and often they’ve built a SaaS solution that will cost substantially less than your engineering time building and maintaining it.
On to how search was terrible. Our content API was never built for search. This is because of the link between our CMS and our content api was only one way: via publishing. Our readers used a managed SOLR cluster for site search. Editorial users only ever needed to work with content inside the CMS, which had reasonable search and categorisation functionality. In the world of Edition Builder existing, suddenly there was a need to find articles before they had gone through the publishing process.
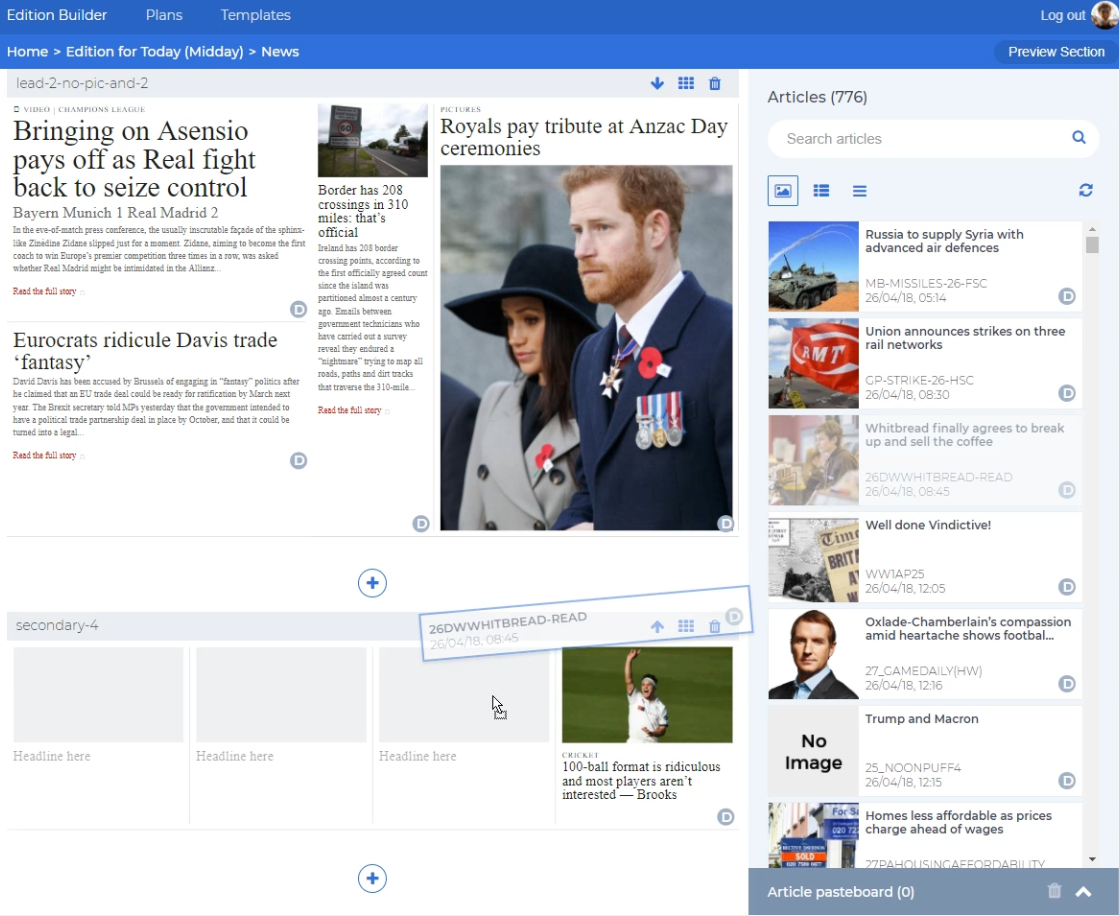
All 776 of those articles were stored in full in your browser’s memory, because performance be damned, we needed somewhere to put them!
“No problem”, we thought, “we’ll set up another version of that API” (because building versioning in to the API was not something we wanted to be responsible for). (and it has ended up coming anyway as part of a later rewrite).
Except of course there was no reasonable way to perform a scan or search as the endpoints just didn’t exist. So in the end we settled for fetching a range of data between two dates, and storing that in the application state to then sift through locally in the browser.
Constructing that index took as long as three seconds per 24hr period searched, so we limited it to three days at a time. Worse: to get new articles, you had to refresh your local index, causing another delay of however long you had selected.
The moment this hit user testing it became clear to us it was a big problem. The search was just too slow. But was it even within our power to fix? We sat on the problem, hoping a solution would rear its head, as every fix we could think of involved work well outside the scope of the project (and adding months to its delivery).
Step forward a couple of months and a couple of members of the team had been tasked with something new. We’d just signed up for Algolia, a SaaS search provider, and needed to get it working for our readers as soon as possible, decommissioning the SOLR cluster as we went.
Algolia is a breeze to work with, and we quickly saw significant improvements on what SOLR had been returning. We feature flagged one engine over the other, and, with journalists being some of the world’s best critics on search engines to surface their own writing, I jerry-rigged a glitch.com app that we sent round to find out which performed better.
A few tweaks to the ranking algorithm later, we were satisfied. And then it dawned on us that we could use exactly the same thing in Edition Builder.
Tearing out the old system and replacing it with a prototype took just a few days. Again we played around with ranking and faceting to get what we needed, and then we threw it in front of users to test. Immediately we saw improvements. A local in-browser index was no-longer necessary. Every query went fresh to the remote index, resulting in more recent results. We could return results almost instantly, just as you typed into the box.
Even better, when users talked about issues they were having with search, they were relatively easy to diagnose. We could replicate the same searches, see how the ranking affected the results, and adjust accordingly, even on a per-query basis.
How we structure edition updates
A second issue we looked to solve focused on how we structured editions. On reflection, I think we could have gone further, and we shouldn’t have shut conversations down so early without seeing them out. Again here there was too much of an assumption we had the best solution at the time, and not enough thought to restructure things early on.
In the previous system, editions over the course of the day were overwritten when the latest update was published. This meant throwing a lot of useful data away, a lot of which we were technically paying for in terms of journalistic decision making. Wouldn’t it potentially be useful to be able to learn about how stories move around the edition, and save different updates separately.
We initially explored a git-style branching system where root editions would have branches with changes on them that then potentially were merged back over time. This had the advantages of immediately making sense to developers, and the disadvantage of it not making any sense to any of our users 😭. Can you imagine playing with git-editions on deadline?!
How a branching model might have enabled multiple versions to work together with each other
The ‘git’ style feature would have brought us some level of historical and history data, which we could have used for scrubbing back and forth, but the complexity add at the time, along with the UI challenges of having this work seamlessly for users was problematic.
We set out to solve the problem actually in front of us, and built the simplest solution we could see that did that.
Our old system never stopped being edition A. In the new system we just create a new edition each time that is a copy of the previous one, whilst saving its parent.
Simply enabling users to copy past published editions into future timeslots solved the data problem, and enabled users to work on future editions whilst still being able to make tweaks and changes to past ones.
In hindsight though, it didn’t solve enough of the problem. For example, in a short timeframe you might want to urgently prepare two options for a future version. A direct copy gives you very little flexibility as other stories that might change need to then be made in two places. We thought at the time about creating overlays you could flatten into an edition update, but again it was difficult to work out if the value would ever be delivered.
Looking back I wish we’d thought harder about how sections interacted with editions and made that less fixed. In reality an edition is just a bundle of sections, and making them updatable independently and then bundleable for an update might have both provided an easier structure to manage, and an easier product to break up should we plan to in the future.
The saving grace at least, given the changes made, is that it will be significantly easier to integrate our bespoke analytics service (INCA) into this system, so as to show journalists when they place stories what the story is expected to do based on its position in terms of our key metrics. This will help journalists understand the power of their decision making better (as stories towards the top of the edition have generally higher numbers than those lower, stories in larger slots likewise etc).
Publishing and the initial breakdown
Finally we have the bug that held us up for four months. The lesson: never trust orphaned systems to do anything.
This is the working version (we also added lazy loading… which would have been a really good idea at the start)
Edition Builder has a feature that shows the entire edition to you at once in a single screen. In order to do this we have to fetch all the articles that exist in this view from the API.
In addition, Edition Builder, for the first time, had to handle published and unpublished content (as mentioned in the search feature). This meant that two versions of the same article could exist at the same time, given editorially you might want to feature either (the unadjusted published version, or the perhaps more-up-to-date unpublished version).
The consequence being this view needed to switch from two sourcing content APIs, the in-production API, and our preview API, depending on the article.
And when we published articles, we switched any reference for this lookup from the preview version to the production version. Simple! When it came to running our first live editions everything went really smoothly. We worked our way back from the 5pm edition to the 9am, in order to have the least impact in the most supportable working hours, and finally had the midnight edition in our sights.
I don’t always @channel, but when I do it’s the best @channel in the world
Where the 9am, 12pm, and 5pm editions are relatively small updates on the main bulk, the midnight edition publishes several hundred articles all at once. For architecture that was not necessarily built for this in mind, bursts like this can be fatal… which we learned to our peril.
😰 👉⏺
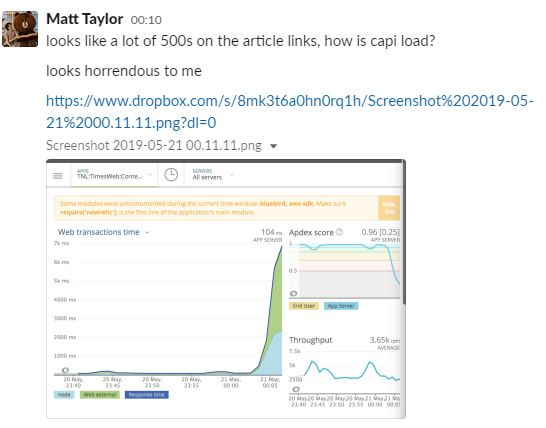
The as-promised ‘crippling load’ 🔥
When Edition Builder publishes the midnight edition, all of these articles get posted into the content API in the same queue. This usually causes a little bit of a spike.
But Edition Builders incredibly smart and well-meaning feature that showed you the entire edition after publish, then immediately tried to load these hundreds of articles from the same system that was trying desperately to ingest them.
And what’s more, in order to check if there were any changes, it reloaded them every thirty seconds.
Cue heavy breathing from our operations team as our apps started to intermittently return 500 errors. And by intermittently, I mean all the time for about fifteen minutes. 😬
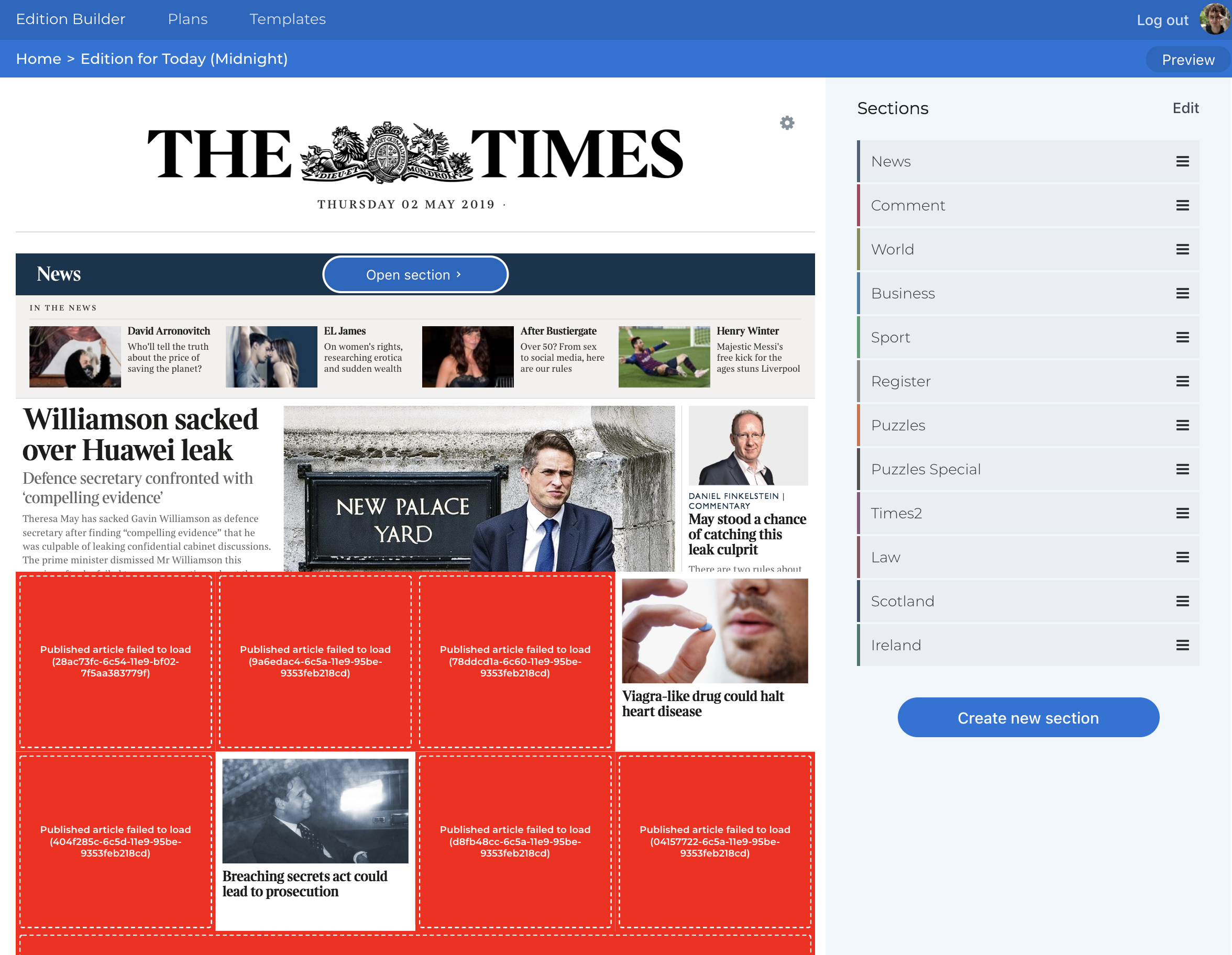
Oh that does not look good.
...
Fixing this was no mean feat. The content API at this stage was practically orphaned, with a replacement on the way, but with no clear end in sight.
What’s more, this problem only occurred in production, and we couldn’t work out how to replicate it on our pre-production instances, which all handled the load fine (perhaps because it was the only load they were seeing 👀).
We, sensibly, were not allowed to continue our production rollout whilst this error still occurred, but we couldn’t replicate the error to show it was solved, so our catch-22 just kept enumerating.
After far too long, our solution came in the form of new talent. Stefano Berdusco joined me on the long road to salvation and together we wrote load tests (he wrote them), we built a perfect replica of production (he build it), and we flipped the sourcing to the new API, so as not to cripple the old one (maybe my idea, but given my track record probably also his).
😍 Our tests, with load applied, showed the new API (built with this burst in mind) was able to easily handle the preview state. And we were back on track.
So that’s that. Thanks for reading, I hope we all learned something. (Also in going through our Slack logs for this post, perhaps my favourite short-lived bug below)

❤️ this team